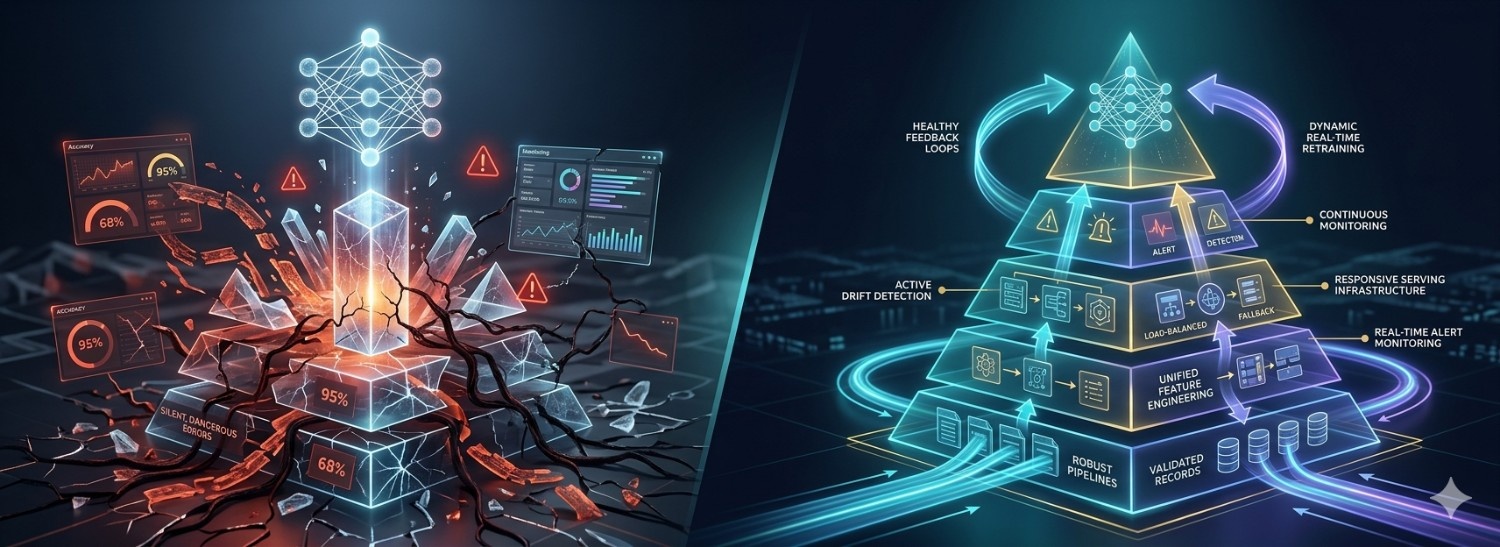
You trained a model that achieves 95% accuracy in the lab. Your team celebrated. You deployed it to production. Three weeks later, it\'s tanking. Accuracy dropped to 68%. Users are complaining. Your CEO is asking questions. Welcome to the AI graveyard—where 70% of machine learning projects fail to reach production, and most of those that do fail within months.
The Real Problem
AI projects fail not because the models are bad, but because teams optimize for accuracy in notebooks while ignoring the operational reality: production is not a controlled lab environment. Data drifts. Predictions must be made at scale. Failures need alerting. Everything requires monitoring.
The five failure modes of production AI
Most AI projects fail for predictable reasons. Not because of bad math, but because of bad systems thinking. Here are the five patterns we see repeatedly:
🔴 Failure Mode 1: Data Drift
Your model trains on 2023 data. By 2024, the world changed. User behavior shifted. The distribution of inputs is no longer what your model expected. Predictions become worse, but your model doesn\'t know it. It keeps making confident guesses that are increasingly wrong. Nobody notices for weeks.
Why it happens: Teams measure accuracy on held-out test data once, then assume the model is "done." In reality, your test set captures one moment in time. The real world keeps moving.
🔴 Failure Mode 2: Silent Failures
Your model encounters an input it\'s never seen before. A feature is missing. A value is out of expected range. The model doesn\'t crash—it just produces garbage predictions. Your application uses them anyway, silently propagating errors downstream. Revenue is lost. Customers are misled. Nobody knows why.
Why it happens: Production data is messier than training data. Your model hasn\'t been instrumented to fail loudly when it encounters edge cases. There\'s no alerting, no dead-letter queue, no visibility.
🔴 Failure Mode 3: Feature Engineering Debt
Your model depends on 50 features. 40 of them are hand-crafted in your training pipeline. When the model moves to production, you need to recompute these features in real-time. They\'re slow. They\'re inconsistent. Your feature computation crashes occasionally. The model serves stale features. Predictions diverge from training.
Why it happens: Training and serving pipelines are built separately. Feature engineering logic isn\'t shared, tested, or versioned. There\'s skew between what the model learned and what it sees in production.
🔴 Failure Mode 4: No Feedback Loop
Your model makes predictions. Those predictions are used by humans or downstream systems. But you never capture what happened as a result. Did the prediction turn out correct? Wrong? The model never learns from its mistakes. It\'s frozen in time, degrading slowly until someone notices.
Why it happens: Connecting predictions to ground truth is hard. It requires instrumentation, data pipelines, and careful bookkeeping. Teams often skip it in favor of getting something live quickly.
🔴 Failure Mode 5: No Rollback Plan
Your model performs poorly in production. You need to roll back to the previous version. Except you don\'t have a previous version. Your deployment process doesn\'t version models. You can\'t easily swap models. You\'re stuck with bad predictions until you can rebuild and redeploy—which takes days or weeks.
Why it happens: Model deployment is treated as a one-time event, not a continuous process. There\'s no versioning infrastructure. No A/B testing setup. No quick rollback mechanism.
Lab Accuracy
95%
on clean test data
Production Reality
68%
after 3 weeks
What successful AI projects actually need
Successful production AI systems are built like a pyramid. The model is the top. Everything below is the foundation that keeps it working:
If any layer is missing, the pyramid collapses. Most projects spend 80% effort on the model and 20% on everything else. Successful projects flip this ratio.
Layer 1: Data infrastructure (the foundation)
Before you train a single model, you need reliable data pipelines. Raw data flowing from sources → staging → cleaned/validated → ready for ML. If this layer isn\'t solid, everything above fails.
What you need:
- Data versioning: Know exactly what data your model trained on. Snapshot versions. Replay ability.
- Data validation: Schema checks, range checks, distribution checks. Catch bad data before it reaches the model.
- Data lineage: Trace where each data point came from. When something goes wrong, you can investigate upstream.
- Data quality metrics: Monitor completeness, uniqueness, timeliness. Alert when data quality degrades.
"Garbage in, garbage out. 70% of your effort should be on data quality, not model sophistication."
Layer 2: Feature engineering (the abstraction)
Features bridge raw data and model predictions. They\'re the most important lever you have—better features beat better algorithms almost every time. But feature engineering is where most production AI systems fail.
The core problem: Training pipelines compute features one way (batch, offline, with historical data). Serving pipelines compute features another way (real-time, online, with live data). The difference—called training-serving skew—silently degrades model performance.
The solution: A shared feature store. Define features once. Use them in both training and serving. Version features. Track dependencies. This is the only way to eliminate skew.
Schema, computation logic, dependencies. Version everything.
Fetch historical features. Train on production data.
Fetch current features. Same computation, same schema.
Open-source options: Feast (Uber), Tecton (commercial). These enforce discipline: features are tracked, versioned, and computed consistently.
Layer 3: Serving infrastructure (the engine)
Your model needs to make predictions at latency and scale requirements. This is non-negotiable. If your model takes 5 seconds to predict and you need predictions in 100ms, it doesn\'t matter how accurate it is—it\'s useless in production.
What you need:
- Model serving: API endpoint that returns predictions in milliseconds. Not a Jupyter notebook. Not a batch job. A production service.
- Containerization: Docker image with model + dependencies. Reproducible deployments. Easy rollbacks.
- Load balancing: Route requests across multiple replicas. Handle traffic spikes. Graceful degradation on failures.
- Fallbacks: When the model fails or is too slow, serve a fallback (previous model, rule-based logic, random). Never return nothing.
Tools: KServe (Kubernetes), Seldon, Ray Serve. Or managed services: AWS SageMaker, GCP Vertex AI, Azure ML.
Layer 4: Monitoring (the watchdog)
You deploy the model. Now what? You monitor. Continuously. Because prediction quality degrades over time as the world changes. You need to know immediately when it happens, not three weeks later.
What to monitor:
| Input distribution drift | Are the features you\'re seeing different from training? Alert if any feature distribution shifts significantly. |
| Prediction distribution shift | Are your predictions becoming biased? Are you predicting class 0 for everything when you used to be balanced? |
| Output quality (when available) | If you can get ground truth (user feedback, labels from downstream system), measure actual accuracy. This is the most important metric. |
| Latency | Is the model getting slower? p95, p99 latency. Alert if degrading. |
| Error rate | Exceptions, timeouts, bad predictions. Track every failure mode. |
| Coverage | What % of requests are you able to serve predictions for? If coverage drops, something is wrong. |
Tools: Evidently AI, WhyLabs, Fiddler (paid), or custom monitoring on Prometheus + Grafana.
Critical rule: Set up monitoring before you deploy. Don\'t wait until something breaks to build dashboards. By then, damage is done.
Layer 5: The feedback loop (continuous improvement)
Monitoring tells you when performance degrades. Retraining fixes it. But retraining is hard. You need:
- Ground truth collection: Mechanism to capture what actually happened after you made a prediction. User feedback, downstream labels, manual review of samples.
- Automated retraining pipelines: Triggered by drift detection or on schedule. Refit model on new data. Validate before deployment.
- A/B testing: Before deploying a new model, run it in shadow mode or on a small traffic slice. Measure performance. Compare to current model.
- Model registry: Version every model. Track which is in production. Enable quick rollbacks.
"Machine learning models decay over time. The only models that stay accurate are the ones that are continuously retrained on fresh data."
The path to production: A checklist
Before you deploy, ask yourself these questions:
🏗️ Foundation
Do you have data pipelines that version data, validate it, and track lineage? Can you reproduce any past dataset?
⚙️ Features
Do you have a feature store or equivalent? Can you fetch the same features in training and serving?
🚀 Serving
Can your model serve predictions with acceptable latency at scale? Do you have fallbacks when it fails?
📊 Monitoring
Do you monitor data drift, prediction drift, latency, and error rates? Are alerts set up to notify you of degradation?
🔄 Feedback Loop
Can you collect ground truth? Can you automatically retrain? Do you version models for easy rollback?
If you answered "no" to any of these, you\'re not ready for production. Don\'t deploy yet. Build the missing layer first. It will take weeks, not hours. That\'s normal and expected.
The unsexy truth about production AI
Building a model that works is 20% of the battle. Making it work in production at scale, with monitoring, retraining, and reliability is 80%. Teams love the first part—Jupyter notebooks, algorithms, leaderboards. They hate the second part—infrastructure, monitoring, operational responsibility.
But you can\'t skip the second part. Not if you want your model to stay alive.
The organizations winning at AI are not the ones with the fanciest models. They\'re the ones with the strongest data infrastructure, the most disciplined feature engineering practices, and the most comprehensive monitoring. They\'ve built systems that catch problems early, recover quickly, and improve continuously.
If you want to join them, stop thinking about models as one-off projects. Think about them as living systems that require constant care, monitoring, and evolution. Build the infrastructure first. Then—and only then—worry about squeezing out the last percentage point of accuracy.
| Data infrastructure | Versioned, validated, lineage-tracked data pipelines feeding models |
| Feature engineering | Shared feature store eliminating training-serving skew |
| Serving infrastructure | Low-latency APIs, containerized models, automatic scaling |
| Monitoring | Drift detection, latency tracking, error alerting from day one |
| Feedback loops | Ground truth collection, automated retraining, A/B testing, quick rollbacks |